# Anna-Sofia Lesiv - A Short History of Artificial Intelligence (Highlights)

## Metadata
**Review**:: [readwise.io](https://readwise.io/bookreview/26179437)
**Source**:: #from/readwise
**Zettel**:: #zettel/fleeting
**Status**:: #x
**Authors**:: [[Anna-Sofia Lesiv]]
**Full Title**:: A Short History of Artificial Intelligence
**Category**:: #articles #readwise/articles
**Category Icon**:: 📰
**Document Tags**:: #favorite # history
**URL**:: [every.to](https://every.to/p/a-short-history-of-artificial-intelligence?ref=refind)
**Host**:: [[every.to]]
**Highlighted**:: [[2023-04-08]]
**Created**:: [[2023-04-10]]
## Highlights
- 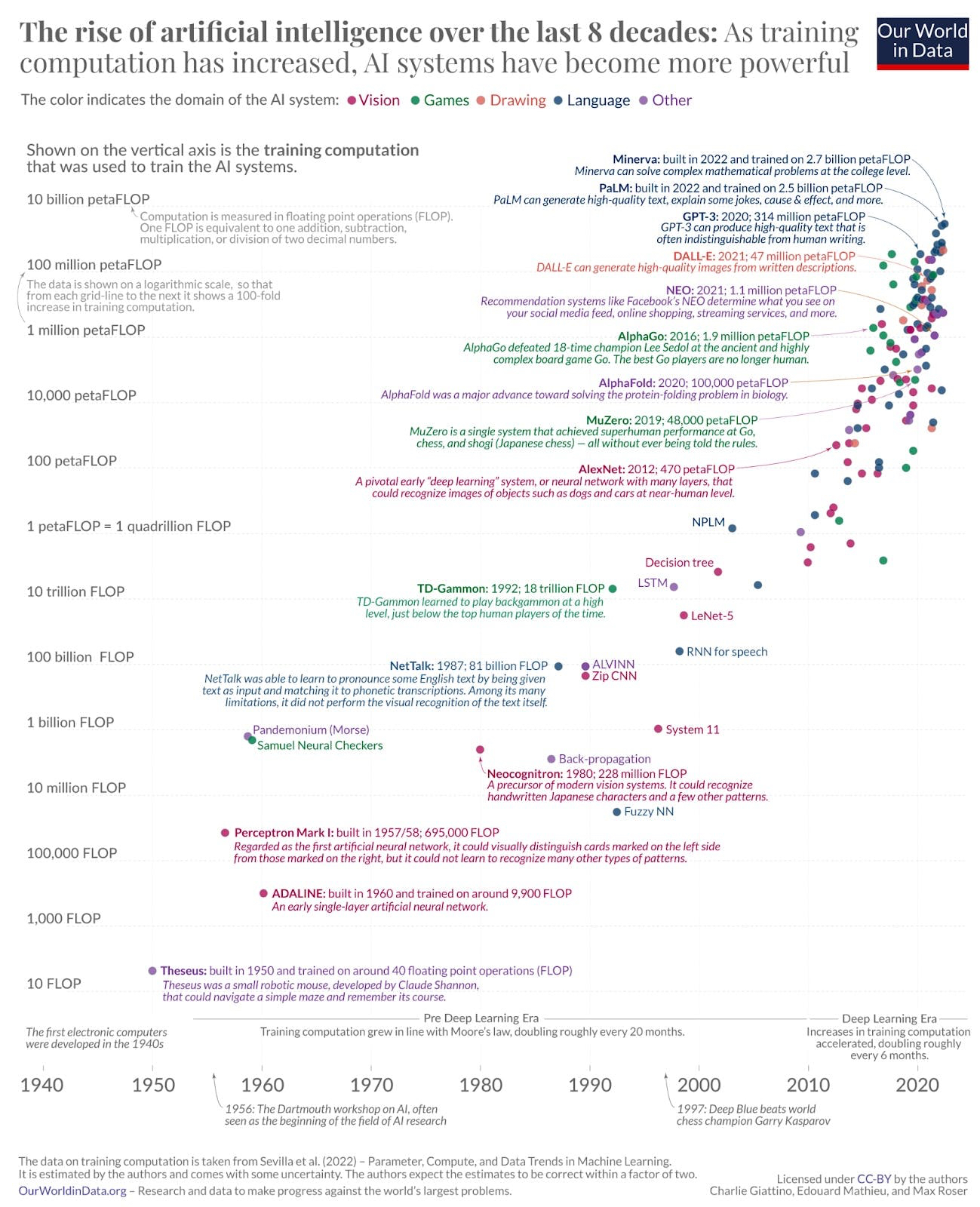 ([View Highlight](https://read.readwise.io/read/01gxf69ecahhy3wa3haj2g4sx4)) ^505203125
- Next a combination of techniques called [back-propagation](https://www.youtube.com/watch?v=Ilg3gGewQ5U) and [gradient descent](https://www.youtube.com/watch?v=IHZwWFHWa-w) are used to guide the function to update its weights such that its overall performance can be improved and performance cost can be minimized. ([View Highlight](https://read.readwise.io/read/01gxf6qyzyx7146akhm0j4nvdg)) ^505204001
- Such decisions are usually determined via a trial-and-error optimization process, but given the massive size of these models, there are other machine learning models trained to adjust these parameters in a process called “[hyperparameter optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization).” ([View Highlight](https://read.readwise.io/read/01gxf6s1kjyd6srhddrbdx6aw8)) ^505204029
- 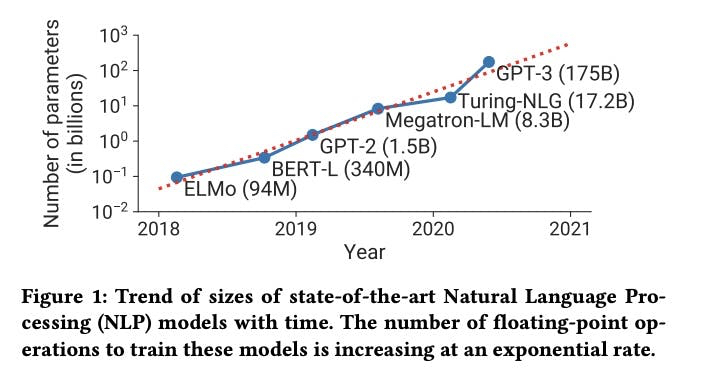 ([View Highlight](https://read.readwise.io/read/01gxf6srr3n5xj33g21smfn6ss)) ^505204050
- Existing neural network structures broke down when trying to crack the nut of language processing. Adding too many layers to a network could mess up the math, making it very difficult to correctly tune models via the training cost function—a side effect known as “[exploding or vanishing gradients](https://en.wikipedia.org/wiki/Vanishing_gradient_problem)” seen in [recurrent neural networks](https://en.wikipedia.org/wiki/Recurrent_neural_network) (RNNs). ([View Highlight](https://read.readwise.io/read/01gxf6ydbpfkz9xjpvb0f1b5n5)) ^505205176
- Rather than breaking an input into smaller pieces, all of which are processed sequentially, the transformer model is instead structured such that every element in the input data can connect to every other element. This way, each layer can decide which inputs to “pay attention to” as it analyzes a document. ([View Highlight](https://read.readwise.io/read/01gxf7163bqfgbn8qct4k27dmw)) ^505205318